Техническая поддержка вебинара: падение сервера



Когда сервер падает, нужно переключиться на OBS и стриминг за 30 секунд. План Б — это профессионализм.
Содержание
- Почему серверы падают на вебинарах
- Архитектура отказоустойчивой системы
- Резервный канал: как его подготовить
- OBS для потокового вещания на случай сбоя
- Техническая поддержка во время события
- Как переключаться между каналами без потери сигнала
- Мониторинг серверов в реальном времени
- Документирование сбоев и их анализ
- Восстановление после критического сбоя
Почему серверы падают на вебинарах
Сервер падает, когда нагрузка превышает пропускную способность или когда есть ошибка в коде. На большом вебинаре это может произойти в самый неудачный момент.
- DDoS-атака: иногда конкуренты атакуют вебинары конкурентов
- Пиковая нагрузка: все подключились одновременно
- Утечка памяти: код имеет баги, память утекает
- Проблемы с БД: запрос к базе данных зависает
- Сбой интернета: провайдер имеет проблему
На одном вебинаре сервер упал из-за неправильно написанного SQL-запроса. Поток запросов взорвал базу. План Б спас положение — люди не заметили проблемы.

Архитектура отказоустойчивой системы
Отказоустойчивая архитектура — это система, которая продолжает работать даже когда часть неё падает.
- Load balancer: распределяет трафик между несколькими серверами
- Несколько зон доступности: серверы в разных центрах обработки данных
- Кеширование: результаты запросов хранятся в памяти
- CDN для видео: контент распределяется по разным точкам
- Мониторинг: скрипты отслеживают здоровье системы 24/7
На стратегических бизнес-сессиях мы используем архитектуру на AWS или Yandex Cloud с redundancy. Даже если один сервер умирает, система работает дальше.
Подарочные боксы к онлайн-корпоративу — https://blog.doctorteam.ru/podarochnye-boksy-k-onlajn-korporativu/
Резервный канал: как его подготовить
Резервный канал — это копия основного потока на другой платформе или сервере.
- Основной канал: Zoom, платформа события, YouTube Live
- Резервный канал 1: Twitch или VK Live
- Резервный канал 2: собственный RTMP-сервер с OBS
- Коммуникация: ссылка на резервный канал в чате и соцсетях
- Переключение: может быть автоматическое или ручное
На презентациях для Сбера используем Zoom как основной и YouTube Live как резервный. Переключение заранее ничего не стоит, а спасает на событии.
OBS для потокового вещания на случай сбоя
OBS (Open Broadcaster Software) — это бесплатное ПО для потокового вещания. Это ваш финальный план Б.
- Захват экрана: OBS берет сигнал с компьютера (ноутбук спикера)
- Микрофон: сигнал с петличного микрофона
- Стриминг: OBS передает на RTMP-сервер (YouTube, Twitch, собственный)
- Задержка: минимум 5-10 секунд на потокового вещание, это нормально
- Резервность: если основной канал дохнет, OBS работает отдельно
На всех наших событиях есть ноутбук с OBS, включенный и готовый. Если платформа падает, за 30 секунд переходим на OBS + YouTube Live.
Геймификация в Zoom: цифровая усталость — https://blog.doctorteam.ru/gejmifikaciya-v-zoom-cifrovaya-ustalost/
Техническая поддержка во время события
Техподдержка во время события — это люди, которые сидят и смотрят на метрики, ждут сбоя.
- IT-инженер: смотрит на логи сервера, CPU, память, базу данных
- Технический райдер: отвечает за оборудование в студии
- Тех-поддержка онлайн: отвечает на вопросы участников в чате
- Режиссер события: координирует всё и знает план Б
- Резервный IT-инженер: спит, но по звонку просыпается за 5 минут
На большом событии в штате 5-7 человек техподдержки. На малом — 2-3. Каждый знает свою роль и план Б. На форумах для клиентов типа Яндекса и Сбера это обязательно.

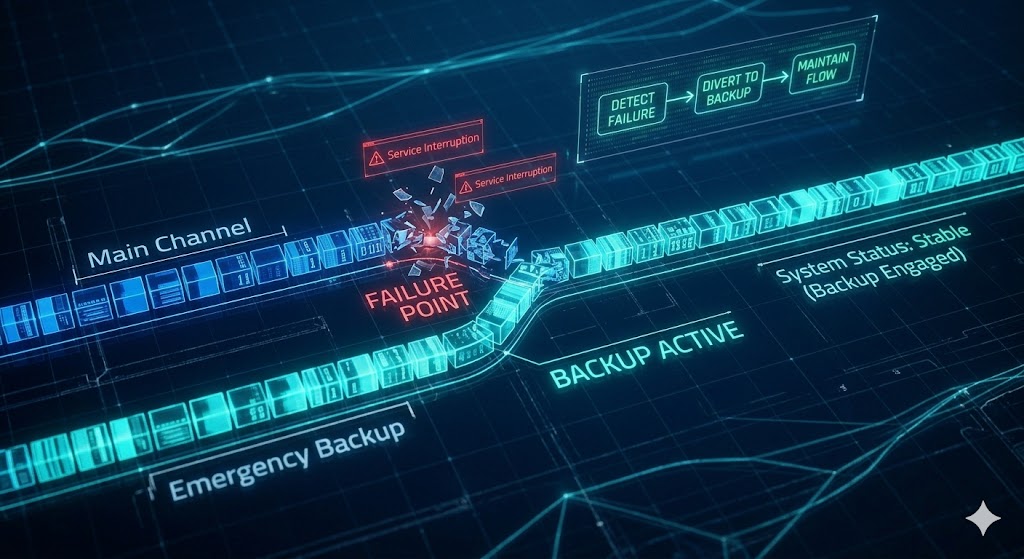
Как переключаться между каналами без потери сигнала
Переключение должно быть быстрым и незаметным для участников. Это требует подготовки.
- Задержка на мониторинг: 10-15 секунд, чтобы обнаружить проблему
- Переключение: 20-30 секунд, чтобы изменить ссылку в чате и соцсетях
- Сообщение участникам: «Технический перерыв, переходим на резервный канал»
- Проверка сигнала: убедиться, что видео и аудио идут правильно
- Продолжение события: начать с того же места, где остановились
На одном событии основной канал упал на 1 минуту. Все перешли на YouTube Live и никто не заметил. Это было возможно потому, что резервный канал был подготовлен.
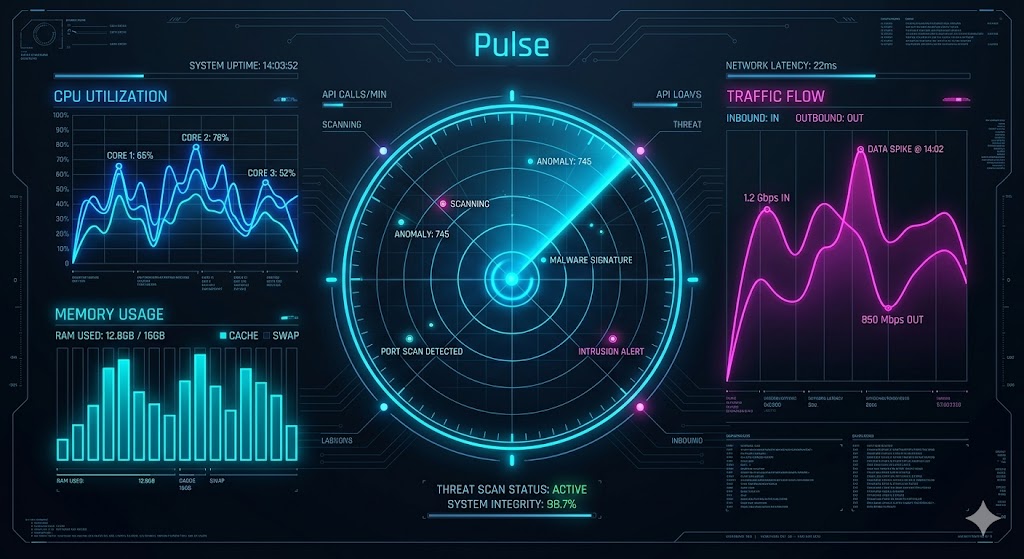
Мониторинг серверов в реальном времени
Мониторинг — это постоянное наблюдение за здоровьем системы. Нужно знать, когда что-то идёт не так.
- Datadog или New Relic: платные сервисы мониторинга
- Prometheus: бесплатный, но нужно настраивать
- Алерты: SMS, пуш, звонок когда CPU > 80% или память утекает
- Логи: все события записываются и можно искать по ним
- Дашборд: графики CPU, память, сетевой трафик, ошибки
На стратегических сессиях мониторинг ведется весь день события. Инженер смотрит на дашборд каждые 30 секунд и готов к действиям.
Документирование сбоев и их анализ
После каждого сбоя нужно документировать, что произошло и как это исправить.
- Timeline: в какую минуту произошёл сбой и как долго он длился
- Причина: что вызвало проблему (DDoS, пиковая нагрузка, баг)
- Решение: что было сделано для решения проблемы
- Root cause: какая была корневая причина
- Улучшения: что нужно поменять, чтобы не было повторения
На одном событии сбой был из-за неправильного кеширования. Задокументировали, исправили код, на следующем событии проблема не повторилась.

Восстановление после критического сбоя
Если сбой был критический и затронул много людей, нужна стратегия восстановления.
- Немедленное сообщение: написать в соцсетях и чате, что произошло
- ETA восстановления: сказать, когда система вернется в строй
- Компенсация: рассмотреть возможность повтора события или скидку
- Пост-мортем: после события провести встречу, что случилось
- Инвестиции: бюджет на улучшение инфраструктуры
На одном вебинаре была 20-минутная остановка. Мы повторили событие на следующий день для всех, кто пропустил. Репутация дороже затрат на повтор.

Часто задаваемые вопросы
Сколько времени на переключение между каналами?
30-60 секунд в лучшем случае. Обнаружить проблему (10 сек), переключиться (20 сек), оповестить людей (20 сек). На следующем чтении сообщение уже в чате.
Может ли OBS стать основным каналом?
Может, но это рискованно. OBS требует ноутбука, микрофона, интернета. Если что-то из этого падает, видео прерывается.
Как сделать автоматическое переключение между каналами?
Нужна система мониторинга, которая отслеживает здоровье основного канала и переключает нагрузку на резервный. Это сложно и требует разработки.
Сколько стоит хорошая инфраструктура для вебинара на 10 000 человек?
AWS или Yandex Cloud: 10-20 тыс. рублей на событие. Добавьте CDN (5-10 тыс.). Итого: 15-30 тыс. Это оправдано, если цена билета выше 1000 рублей.
Что делать, если резервный канал тоже упал?
Это апокалипсис. OBS + YouTube Live остается последней надеждой. Но вероятность падения двух независимых систем одновременно очень мала.
Итог:
- Резервные системы обязательны на большие события.
- OBS это финальный план Б, когда всё остальное падает.
- Мониторинг в реальном времени спасает события.
- Техподдержка должна быть готова 24/7.
- Документирование сбоев помогает улучшать инфраструктуру.
Хотите, чтобы ваше мероприятие прошло без форс-мажоров? Оставьте заявку на doctorteam.ru — мы разработаем программу с планом Б под любой сценарий.
Напишите нам: info@doctorteam.ru
В Telegram-канале eventstory_by мы делимся экспертизой по организации научных и деловых мероприятий, разбираем реальные кейсы и показываем, как усиливать формат через детали.
____
Автор: Игорь Иванов, DoctorTeam. Статья основана на опыте проведения масштабных вебинаров и событий с критической инфраструктурой.